|
I am a research scientist at Google Deepmind. Prior to Google Deepmind, I spent two years at Microsoft working on vision foundation models. Featured projects include FLorence and ClipBERT. I received my Ph.D. degree from University of Michigan in 2020, under the supervision of Dr. Jason J. Corso. I worked on projects including vision-language pre-training (Unified VLP), YouCook2, and one of the first Visual Transformers (densecap). I received my bachelor's degree from Nanjing University in 2015, where I worked on Multi-Agent RL. I spent summer interns at FAIR, MSR, and Salesforce Research. I am one of the winners of CVPR 2021 Best Student Paper HM. |

|
|
|
|
I'm interested in computer vision and its relations to natural language and deep learning, with a focus on learning visual representation from multimodal supervision. Problems of interest include multimodal learning (e.g., captioning, grounding, VQA), video understanding, unsupervised representation learning, generative models, and Transformers etc. |
|
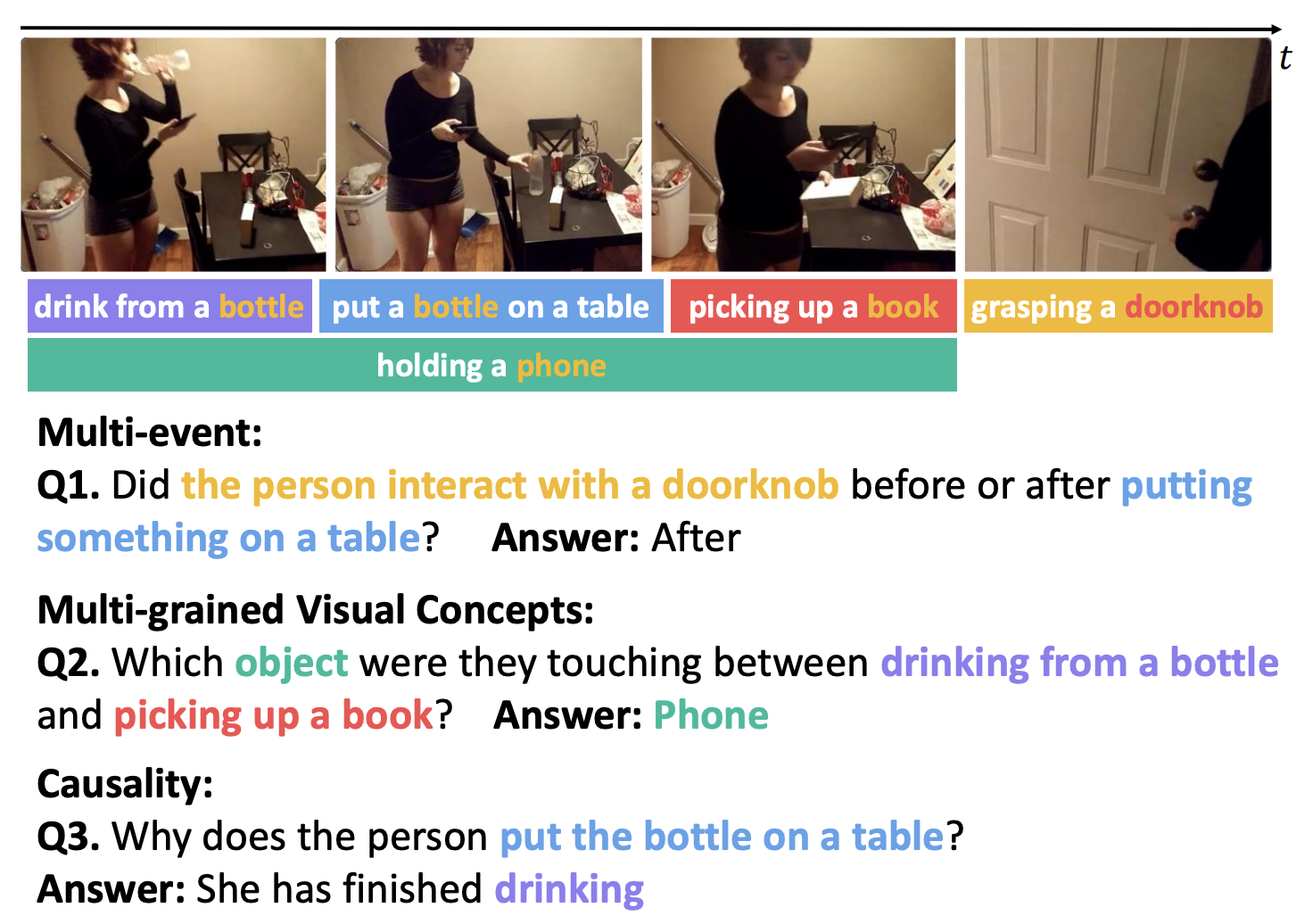
Difei Gao, Luowei Zhou, Lei Ji, Linchao Zhu, Yi Yang, Mike Zheng Shou CVPR, 2023 |
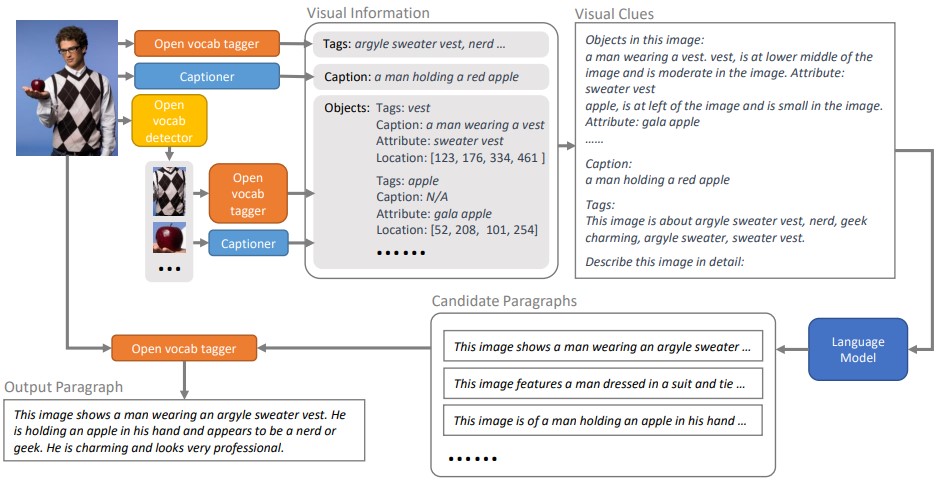
|
Yujia Xie, Luowei Zhou, Xiyang Dai, Lu Yuan, Nguyen Bach, Ce Liu, Michael Zeng NeurIPS, 2022 PDF / Examples / Covered by The Economist |

|
Zhenhailong Wang, Manling Li, Ruochen Xu, Luowei Zhou, Jie Lei, Xudong Lin, Shuohang Wang, Ziyi Yang, Chenguang Zhu, Derek Hoiem, Shih-Fu Chang, Mohit Bansal, Heng Ji NeruIPS, 2022 PDF / Code |
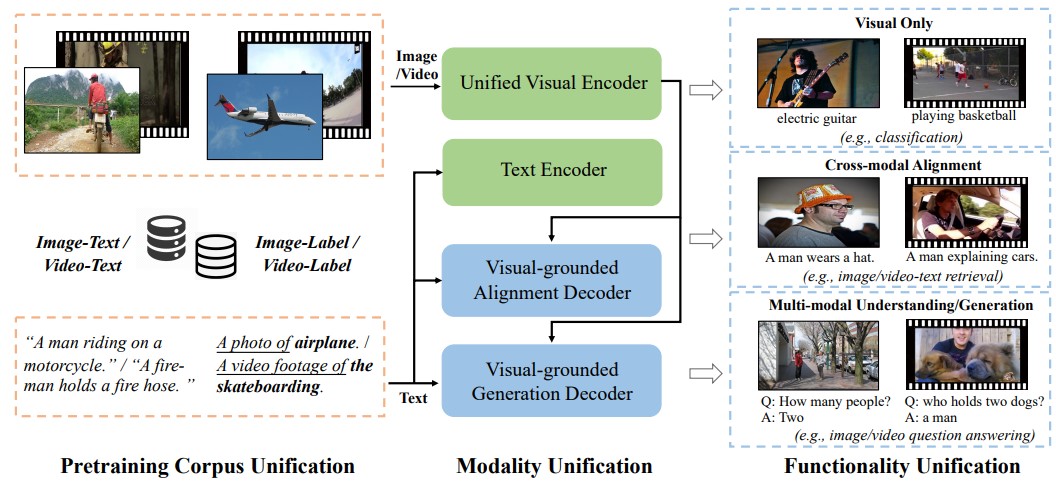
|
Junke Wang, Dongdong Chen, Zuxuan Wu, Chong Luo, Luowei Zhou, Yucheng Zhao, Yujia Xie, Ce Liu, Yu-Gang Jiang, Lu Yuan NeurIPS, 2022 |
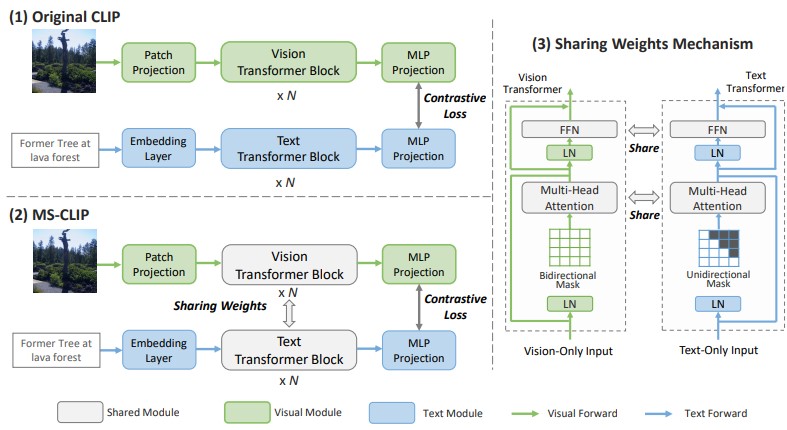
|
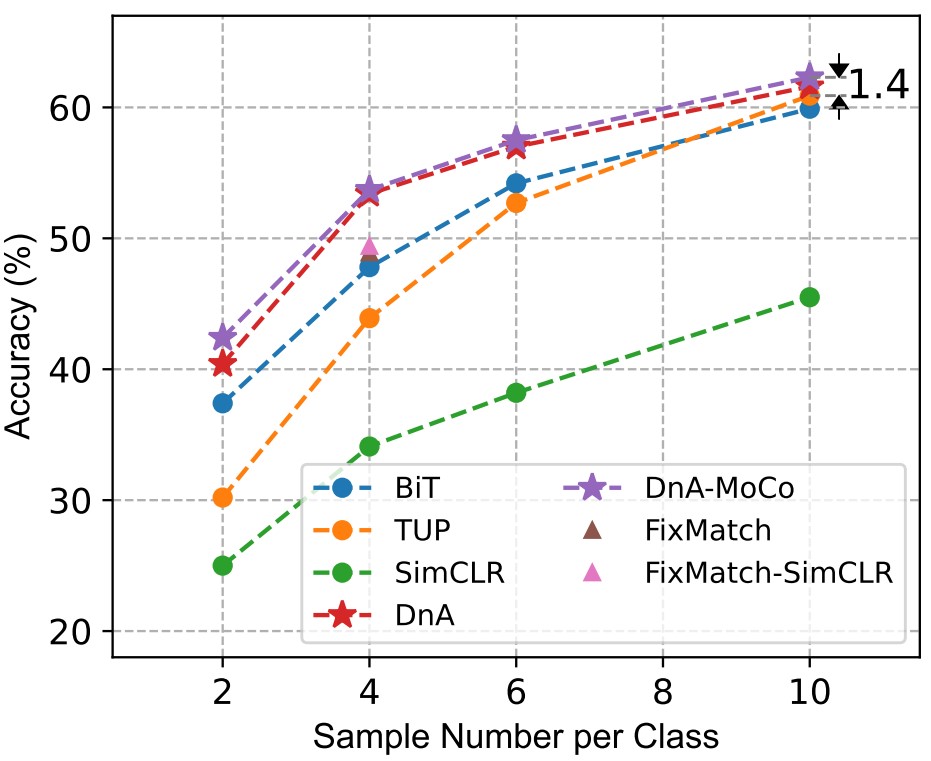
Haoxuan You*, Luowei Zhou*, Bin Xiao*, Noel Codella*, Yu Cheng, Ruochen Xu, Shih-Fu Chang, Lu Yuan ECCV, 2022 PDF / Code |
|
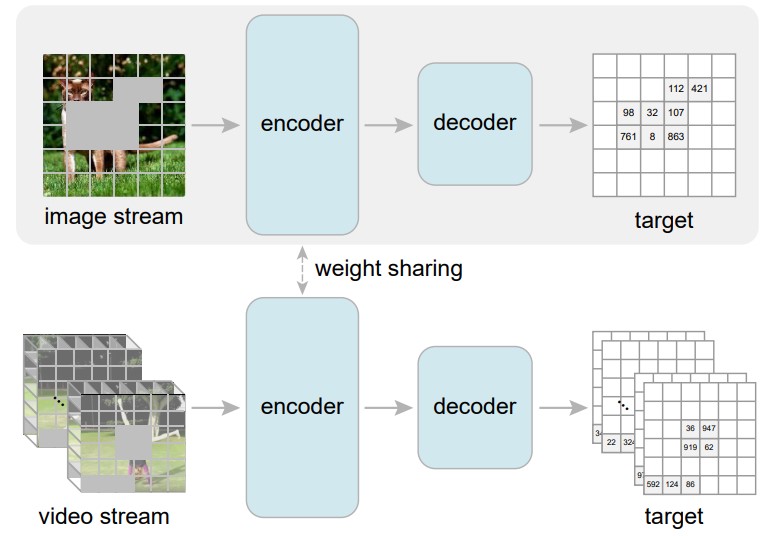
Ziyu Jiang, Tianlong Chen, Xuxi Chen, Yu Cheng, Luowei Zhou, Lu Yuan, Ahmed Awadallah, Zhangyang Wang ECCV, 2022 |
|
Rui Wang, Dongdong Chen, Zuxuan Wu, Yinpeng Chen, Xiyang Dai, Mengchen Liu, Yu-Gang Jiang, Luowei Zhou, Lu Yuan CVPR, 2022 PDF / Code |
|
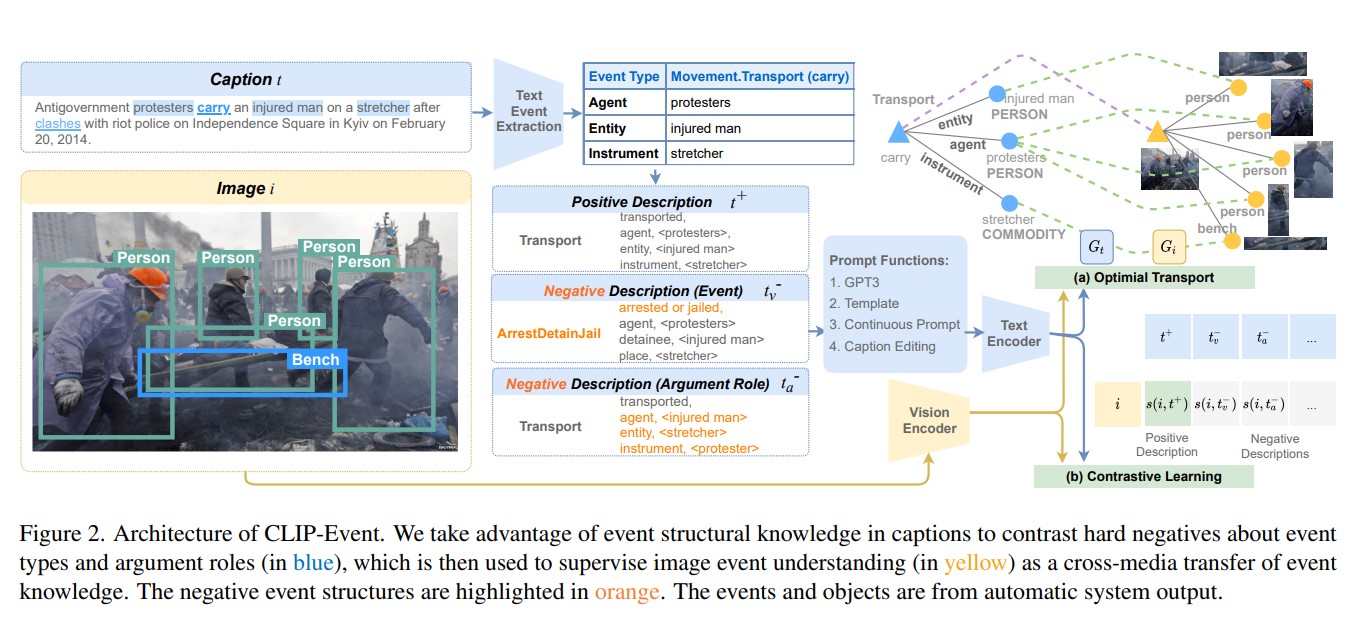
Manling Li, Ruochen Xu, Shuohang Wang, Luowei Zhou, Xudong Lin, Chenguang Zhu, Michael Zeng, Heng Ji, Shih-Fu Chang CVPR, 2022 (Oral) PDF / Code |

|
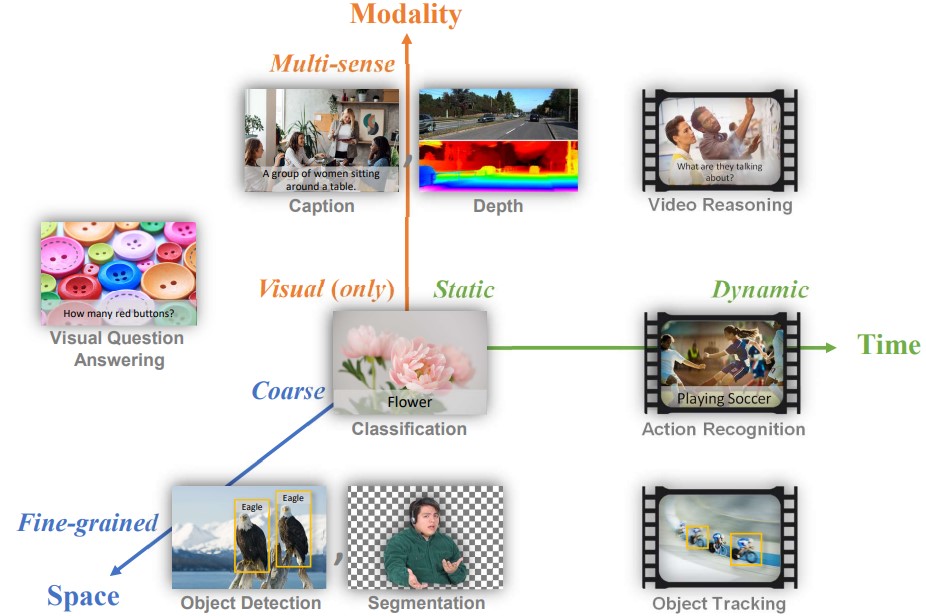
Yiwu Zhong, Jianwei Yang, Pengchuan Zhang, Chunyuan Li, Noel Codella, Liunian Harold Li, Luowei Zhou, Xiyang Dai, Lu Yuan, Yin Li, Jianfeng Gao CVPR, 2022 PDF / Code |
|
|
Nathan Louis, Luowei Zhou, Steven J Yule, Roger D Dias, Milisa Manojlovich, Francis D Pagani, Donald S Likosky, Jason J. Corso IJCARS, 2022 PDF / Code |
|
Lu Yuan, Dongdong Chen, Yi-Ling Chen, Noel Codella, Xiyang Dai, Jianfeng Gao, Houdong Hu, Xuedong Huang, Boxin Li, Chunyuan Li, Ce Liu, Mengchen Liu, Zicheng Liu, Yumao Lu, Yu Shi, Lijuan Wang, Jianfeng Wang, Bin Xiao, Zhen Xiao, Jianwei Yang, Michael Zeng, Luowei Zhou, Pengchuan Zhang arXiv, 2021 PDF / Azure Blog / XD's CVPR'22 Keynote / Synced |
|
Jie Lei, Linjie Li, Luowei Zhou, Zhe Gan, Tamara L Berg, Mohit Bansal, Jingjing Liu Best Student Paper Honorable Mention award CVPR, 2021 (Oral)PDF / Code |
|
Mingyang Zhou, Luowei Zhou, Shuohang Wang, Yu Cheng, Linjie Li, Zhou Yu, Jingjing Liu CVPR, 2021 PDF / Code |
|
Linjie Li, Jie Lei, Zhe Gan, Licheng Yu, Yen-Chun Chen, Rohit Pillai, Yu Cheng, Luowei Zhou, Xin Eric Wang, William Yang Wang, Tamara Lee Berg, Mohit Bansal, Jingjing Liu, Lijuan Wang, Zicheng Liu NeurIPS, 2021 PDF / Benchmark / ICCV'21 Challenge |
|
Shuohang Wang, Luowei Zhou, Zhe Gan, Yen-Chun Chen, Yuwei Fang, Siqi Sun, Yu Cheng, Jingjing Liu ACL (Findings), 2021 |

|
Luowei Zhou Dissertation, 2020 PDF / Defense Recording |
|
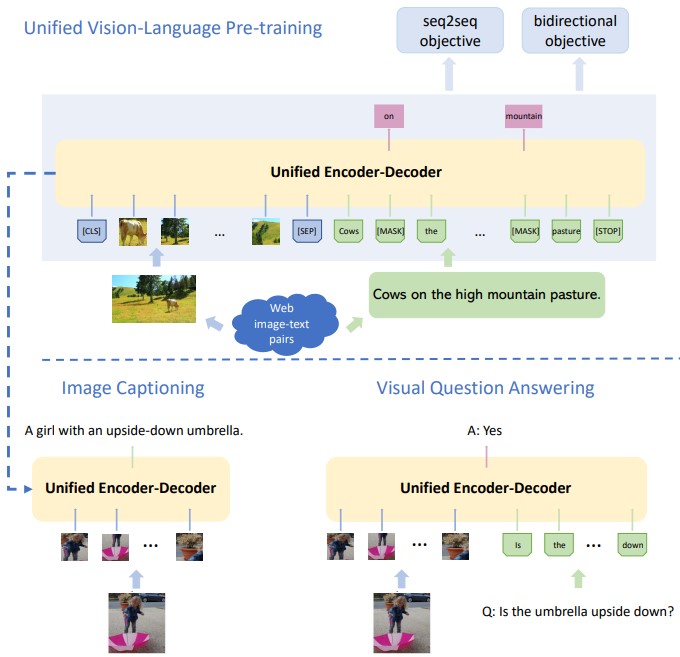
Luowei Zhou, Hamid Palangi, Lei Zhang, Houdong Hu, Jason J. Corso, Jianfeng Gao AAAI, 2020 (Spotlight) PDF / Code / MSR Blog / VentureBeat |

|
Luowei Zhou, Yannis Kalantidis, Xinlei Chen, Jason J. Corso, Marcus Rohrbach CVPR, 2019 (Oral) PDF / Code / ActivityNet-Entities dataset / CVPR'20 Challenge / CVPR'21 Challenge |
|
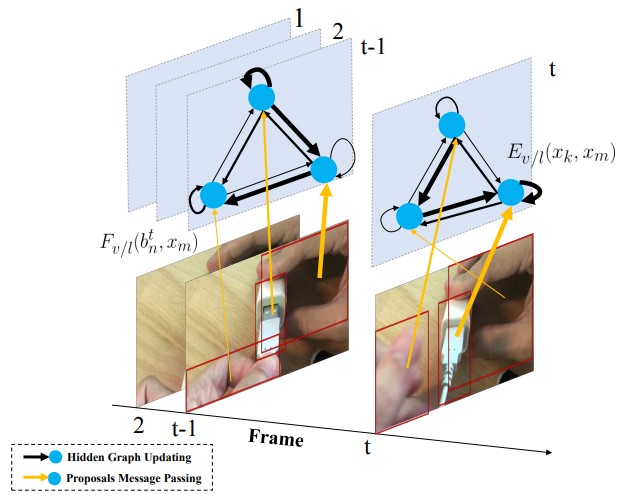
Hao Huang, Luowei Zhou, Wei Zhang, Jason J. Corso, Chenliang Xu BMVC, 2019 |
|
Luowei Zhou*, Yingbo Zhou*, Jason J. Corso, Richard Socher, Caiming Xiong CVPR, 2018 (Spotlight) PDF / Code |
|
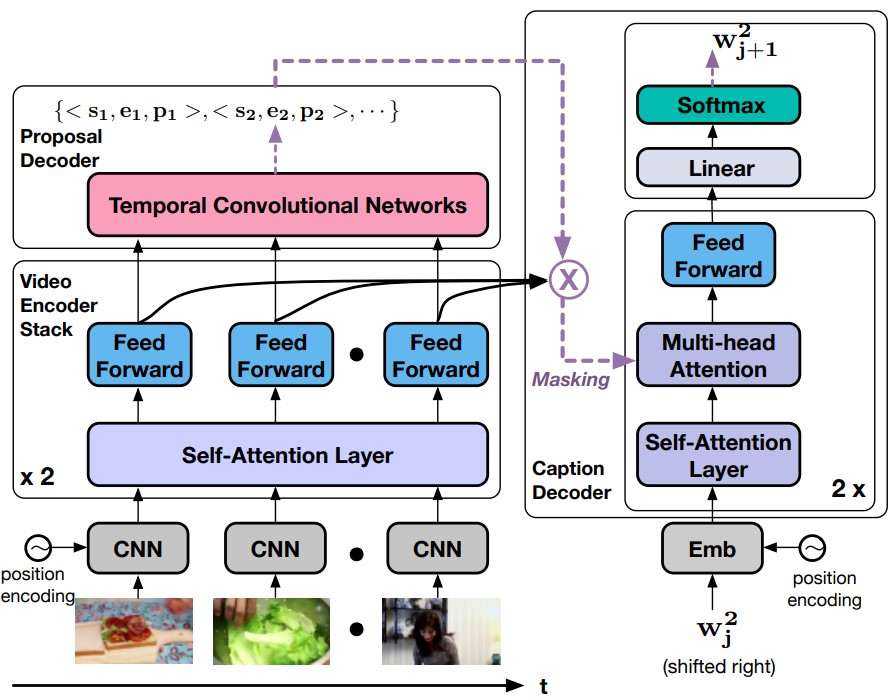
Luowei Zhou, Chenliang Xu, Jason J. Corso AAAI, 2018 (Oral) PDF / Code / YouCook2 dataset / Leaderboard |
|
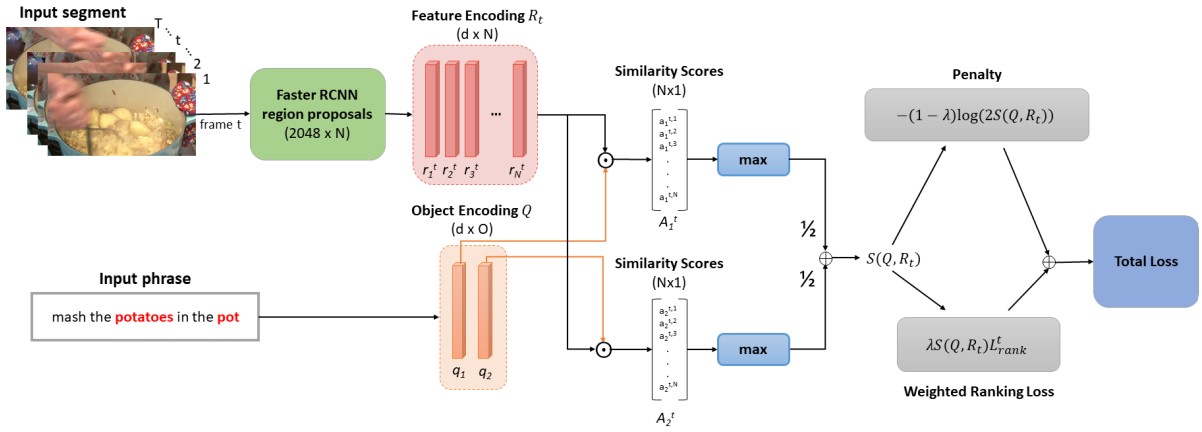
Luowei Zhou, Nathan Louis, Jason J. Corso BMVC, 2018 PDF / Code / YouCook2-BB dataset |
|
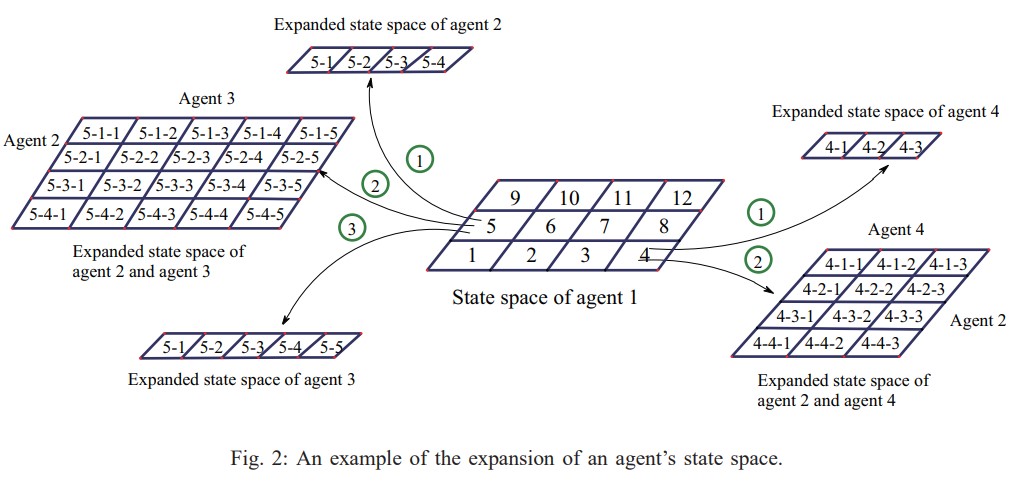
Luowei Zhou, Pei Yang, Chunlin Chen, Yang Gao Journal Impact Factor: 19.12 IEEE Transactions on Cybernetics, 2017PDF / Code |
|
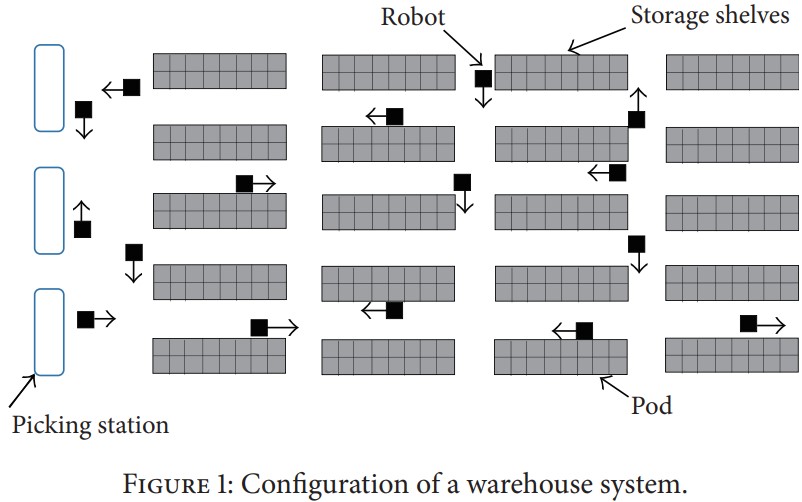
Luowei Zhou, Yuanyuan Shi, Jiangliu Wang, Pei Yang MPE, 2014 |
|
|